- Le billet sur le blog de Renaud Hermal, journaliste de DH Net et La Libre
- Blogging the news : billet 1 et billet 2
Technorati Tags: poursuite, google, belgique, journaux+belges, copiepresse
"On demande rémunération et autorisation à partir du moment où ils vendent de la publicité et s'enrichissent sur notre contenu", a déclaré lundi à Reuters la secrétaire générale de Copiepresse, Margaret Boribon.Après avoir été condamné pour la mise en ligne d'articles belges sur Google News Belgique, Google a tout simplement décidé de faire disparaître ces journaux de son index en Belgique.
Aux termes du jugement, Google devra donc retirer à partir de lundi tous les articles, représentations graphiques ou photographies des éditeurs belges de la presse francophone, sous peine de devoir payer un million d'euros par jour de retard.
Premièrement, qu'une compagnie de service n'est pas nécessairement une compagnie capable de profiter du dialogue. Elle doit pour ça être ouvert à l'écoute. Ou plutôt que l'écoute soit un vecteur important pour sa croissance. Une boîte de RP (comme Edleman) l'est, par définition - elle doit être à l'écoute du marché.Effectivement, comme dans la majorité du secteur des affaires au Québec, très peu de joueurs sont à l'écoute du Web. C'est même exaspérant dans le secteur de la publicité, où seulement une infime part de leurs employés utilisent les carnets Web pour suivre les tendances du marché. Et c'est exactement la même chose pour les sites Web en général. Demande à n'importe quel patron le nombre de visiteurs que son site reçoit ? Il y a 8 chance sur 10 qu'il ne le sache pas où qu'il te donne des chiffres farfelus.
Deuxièmement, qu'une compagnie qui ne comprend pas ce qui m'enrichit n'est pas faite pour moi. Dont acte.
 * Visible aux États-Unis seulement.
* Visible aux États-Unis seulement.


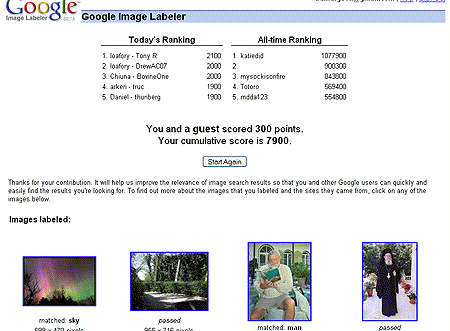 Certains en doute, mais moins de 100 heures après le lancement du jeu, les 5 joueurs les plus "intoxiqués" par ce jeux ont déja étiquetés, - à eux cinq seulement-, près de 50,000 images !
Certains en doute, mais moins de 100 heures après le lancement du jeu, les 5 joueurs les plus "intoxiqués" par ce jeux ont déja étiquetés, - à eux cinq seulement-, près de 50,000 images !