L'Université de la Californie à Berkeley a maintenant une section sur Google Vidéo où elle présente plus de 225 vidéos de cours, symposiums et conférences.
Technorati Tags: google+vidéo, berkeley, université, cours
26 sept. 2006
S'inscrire gratuitement à Google Maps
Il est très simple et assez rapide pour s'inscrire et d'avoir sa fiche sur Google Maps. Celle-ci comprend :
Il faut simplement avoir un compte chez Google et ensuite aller ici (Pour nos voisins américain c'est ici) et tout simplement entrer les informations ci-haut, ensuite choisir une ou plusieurs catégories reliées à vos produits ou services. Ensuite vous choisissez la méthode de vérification que vous préférez, soit par la poste sous forme de carte postale ou encore par le système téléphonique automatisé de Google.
C'est que j'ai choisit et j'ai reçu un appel automatique de Google où l'on doit entrer par le clavier du téléphone le NIP qui apparaît sur la page Web de confirmation de l'information. Et voilà ! Il ne reste qu'a attendre que Google Maps intègre votre fiche, dans mon cas moins d'une semaine plus tard !
L'inscription gratuite à Google Maps peut générer passablement de pages vues par mois et un taux de clic vers votre site ou d'appel téléphonique en moyenne supérieure à une bannière publicitaire. Il faut bien utiliser le maximum des cinq catégories possible et n'hésiter pas à créer la votre si elle n'est pas disponible dans la liste des catégories de Google Maps.


Technorati Tags: google+maps
- Son nom d'entreprise
- L'adresse complète
- Un lien vers son site
- Les méthodes de paiement acceptées
- Une courte description
- Des coupons rabais (pas testé encore)
Il faut simplement avoir un compte chez Google et ensuite aller ici (Pour nos voisins américain c'est ici) et tout simplement entrer les informations ci-haut, ensuite choisir une ou plusieurs catégories reliées à vos produits ou services. Ensuite vous choisissez la méthode de vérification que vous préférez, soit par la poste sous forme de carte postale ou encore par le système téléphonique automatisé de Google.
C'est que j'ai choisit et j'ai reçu un appel automatique de Google où l'on doit entrer par le clavier du téléphone le NIP qui apparaît sur la page Web de confirmation de l'information. Et voilà ! Il ne reste qu'a attendre que Google Maps intègre votre fiche, dans mon cas moins d'une semaine plus tard !
L'inscription gratuite à Google Maps peut générer passablement de pages vues par mois et un taux de clic vers votre site ou d'appel téléphonique en moyenne supérieure à une bannière publicitaire. Il faut bien utiliser le maximum des cinq catégories possible et n'hésiter pas à créer la votre si elle n'est pas disponible dans la liste des catégories de Google Maps.
Technorati Tags: google+maps
Publicité dynamique 2.0
Novatrice la nouvelle forme de publicité dynamique inventé par Gabe Rivera de TechMeme. Contrairement à la traditionelle publicité insérée dans un fil RSS, c'est plutôt le dernier billet du Sponsor qui est affiché dans la colonne de droite sur la page de Techmeme. Ainsi l'annonceur peut modifier à volonté sa publicité par l'ajout d'un nouveau billet sur son blog et qui est automatiquement transposé sur le site de Techmeme. Il en coûte de $4,500 à $3,000, - selon la position -, pour trois mois pour les annonceurs. Comme le mentionne Jeff Jarvis, c'est une aubaine !
La grande force de ce nouveau concept est qu'il permettra aussi de synchroniser ses publicités avec les sujets du jour qui populent Techmeme. Bravo et très bonne idée !
Technorati Tags: publicité+2.0, publicité+dynamique, techmeme, publicité+rss
La grande force de ce nouveau concept est qu'il permettra aussi de synchroniser ses publicités avec les sujets du jour qui populent Techmeme. Bravo et très bonne idée !
Technorati Tags: publicité+2.0, publicité+dynamique, techmeme, publicité+rss
25 sept. 2006
La fraude aux clic$ fait la une de Business Week
Très bon article qui vulgarise assez bien les diverses technique utilisées par les fraudeurs pour se faire des sous sur le dos des annonceurs dans ce marché qui atteind maintenant plusieurs milliards de dollars.
20 sept. 2006
Google vs Belgique : Vive les vieilles autruches
Voici un très bon passage de l'article et entrevue de Danny Sullyvan avec la porte-parole de CopiePresse, l'autruche en question :
Je ne peux pas croire que des médias n'essais pas de trouver des solutions originales (sans passer par la voix des tribunaux) face au fait que les moteurs de recherches profitent à tous le monde et sont essentiels à notre patrimoine culturel et informationels mondial.
J'étais déjà estomaquer à l'époque ou en 2001-2002 d'apprendre que l'IAB ne reconnaissait pas le téléchargement de PDF de journaux et de leurs publicités comme étant de la copie distribué*.
Merde, réveillez-vous.
Une des nombreuses solutions facilement applicables des deux cotés pour la libre circulation:
Vous obligez Google news a publier aussi l'annonce de votre régie publicitaire provenant de votre section Monde de 100 x 200 pixels pour un résumé de 100 mots. Ou encore 200 x 600 pixels pour 400 mots ? Google l'aspire comme votre résumé et votre "tracker" assure la page vue et aussi le "click thru". Techniquement compliquer ? Vraiment pas !
Votre annonceur est uniquement local ? Vous passer une entente avec Google News de votre pays uniquement pour une entente similaire avec plus ou mois "d'exposure" publicitaire et partage des revenus.
*Et dire que maintenant la plupart des journaux des grands médias vous donnent des copies gratuites à tour de bras dans n'importe quels évènements et même dans les ventes trottoir de Montréal pour ne pas voir leur nombre de copies décroitre et se faire baisser leur cotes !
Technorati Tags: copiepresse, google, belgique, medias, libre+circulation
I had a very long conversation about the permissions issue with Margaret Boribon, secretary general of Copiepresse, to try and better understand how they wanted Google to operate. Why not use commonly understood and effective mechanisms such as robots.txt files or meta robots tags to prevent indexing?
"If you do so, you admit that Google does what they want, and if you don't agree, you have to contact them. This is not the legal framework of copyright," Boribon said.
This is an age old issue in the search engine world. By default, search engines assume that permission is granted to index a document, in order to make it searchable. Technically, shouldn't they get explicit permission? Legally, that might make things safer. Logistically, it would never work. Many sites don't have clear contact details. Some domains themselves contain multiple sites. Moreover, there are millions of sites across the web. Contacting them all beforehand simply wouldn't work well.
I asked Boribon about this, how her group would propose search engines undertake such a task.
"I'm sure they can find a very easy system to send an email or a document to alert the site and ask for permission or maybe a system of opt-in or opt-out," she said.
Would it be OK for such a system to work automatically, I asked? Yes, that would be fine. A machine-to-machine connection would be OK, she said. So then, I asked, why not use the existing robots.txt or meta robots systems?
Both mechanisms are easy, automatic ways for publishers to declare if they grant indexing permission or not. In fact, I'd argue that both are a way for search engines to ask beforehand for the very permission that Copiepresse wants them to seek. Major search engines -- not just Google -- all request or check these blocking mechanisms.
Boribon rejected the existing solutions. One issue she had was that they weren't legally endorsed. That's true, but that's also something I think will change over time. In the US, we've had one case recently where opt-out solutions like tags have been accepted.
Je ne peux pas croire que des médias n'essais pas de trouver des solutions originales (sans passer par la voix des tribunaux) face au fait que les moteurs de recherches profitent à tous le monde et sont essentiels à notre patrimoine culturel et informationels mondial.
J'étais déjà estomaquer à l'époque ou en 2001-2002 d'apprendre que l'IAB ne reconnaissait pas le téléchargement de PDF de journaux et de leurs publicités comme étant de la copie distribué*.
Merde, réveillez-vous.
Une des nombreuses solutions facilement applicables des deux cotés pour la libre circulation:
Vous obligez Google news a publier aussi l'annonce de votre régie publicitaire provenant de votre section Monde de 100 x 200 pixels pour un résumé de 100 mots. Ou encore 200 x 600 pixels pour 400 mots ? Google l'aspire comme votre résumé et votre "tracker" assure la page vue et aussi le "click thru". Techniquement compliquer ? Vraiment pas !
Votre annonceur est uniquement local ? Vous passer une entente avec Google News de votre pays uniquement pour une entente similaire avec plus ou mois "d'exposure" publicitaire et partage des revenus.
*Et dire que maintenant la plupart des journaux des grands médias vous donnent des copies gratuites à tour de bras dans n'importe quels évènements et même dans les ventes trottoir de Montréal pour ne pas voir leur nombre de copies décroitre et se faire baisser leur cotes !
Technorati Tags: copiepresse, google, belgique, medias, libre+circulation
Réveil Belge douloureux
Voici quelques réactions des Belges sur l'affaire Google vs CopiePresse (Belgique).
Technorati Tags: poursuite, google, belgique, journaux+belges, copiepresse
- Le billet sur le blog de Renaud Hermal, journaliste de DH Net et La Libre
- Blogging the news : billet 1 et billet 2
Technorati Tags: poursuite, google, belgique, journaux+belges, copiepresse
19 sept. 2006
Les journaux Belges radiés de Google Belgique
"On demande rémunération et autorisation à partir du moment où ils vendent de la publicité et s'enrichissent sur notre contenu", a déclaré lundi à Reuters la secrétaire générale de Copiepresse, Margaret Boribon.Après avoir été condamné pour la mise en ligne d'articles belges sur Google News Belgique, Google a tout simplement décidé de faire disparaître ces journaux de son index en Belgique.
Aux termes du jugement, Google devra donc retirer à partir de lundi tous les articles, représentations graphiques ou photographies des éditeurs belges de la presse francophone, sous peine de devoir payer un million d'euros par jour de retard.
Le hic est que Google News n'a jamais eu de publicité ! Et vlan dans les dents, car maintenant et Google News et l'index principal de Google Belgique ne contiennent plus de nouvelles et de pages indexées de ces journaux !
J'approuve à 100%.
Certains comme Associated Press et Le Monde ont fait autrement et ont conclus des ententes avec Google. Mais le meilleur modèle me semble tout de même celui d'un acteur local, le journal Le Devoir qui apparaît dans Google News mais ou certains de ses articles sont visibles en totalité uniquement avec abonnement. Ceci conjugué avec la mise en ligne de plus de trois annés d'archives du journal, a fait plus que centupler ses visiteurs provenant de Google ce qui est beaucoup plus profitable au niveau publicitaire.
J'espère que ce dernier modèle d'affaire fera réfléchir plusieurs autres médias et qu'un jour on pourra en arriver à ceci.
Qu'on se le dise bien, quand on met quelque chose sur le Web, on est suceptible de se le faire accaparer. On doit penser à adapter nos modèles d'affaires pour le Web.
Technorati Tags: google+belgique, google, belgique, radier, purge
18 sept. 2006
La Chine est probablement LA plus branché
Sceptique ?
Données tiré de l'excellent bulletin Guanxi (PDF) de la firme américaine Berkshire aidé d'une firme d'analyse de statistiques WOM (Word of Mouth) bien branché sur la Chine et qui confirme plusieurs articles et billets que j'ai consulté dans les derniers mois sur la montée fulgurante des pays asiatiques et spécialement de la Chine sur le Web:
Données tiré de l'excellent bulletin Guanxi (PDF) de la firme américaine Berkshire aidé d'une firme d'analyse de statistiques WOM (Word of Mouth) bien branché sur la Chine et qui confirme plusieurs articles et billets que j'ai consulté dans les derniers mois sur la montée fulgurante des pays asiatiques et spécialement de la Chine sur le Web:
- 40,000,000 utilisateurs de forums
- 6,000,000 de bloggeurs
- Utilisateurs (classique et mobile) : Entre 150 et 200 M (US Jan. 2006 : 154 M)
- Heures en ligne par semaine : 2 milliards (US : 129 millions)
- Flickr : Environ 500,000 photos sont téléchargés par jour
- Cyworld (Corée, Chine, Japon et un peu au US) : Près de 6.2 millions de photos sont téléchargés par jour
Google NetPAC : A l'assaut du plus grand défi
Très bon papier du San Francisco Chronicle sur la nouvelle initiative de Google pour se (re)faire une crédibilité, - du point de vue républicain -, en formant un comité d'action politique pour la promotion de la liberté d'expression sur Internet. C-a-d du vrai lobbying !
Technorati Tags: netpac, lobbying, google
Technorati Tags: netpac, lobbying, google
YouTube le prochain Napster ?
C'est du moins ce qu'en pense Mark Cuban et je dois admettre qu'il n'a pas tout à fait tord !
La comprehension du Web au Quebec
À la suite de la lecture du, - excellent comme toujours -, billet Le retour des intermédiaires de Martin, les conclusions qu'il décrit ne me surprennent pas trop pour avoir évoluez avec quelques acteurs de son industrie.
C'est exactement la même chose pour les producteurs de sites Web. Plus de 90% des boites qui concoivent des sites Web ne pensent pas a rendre les sites de leurs clients conviviaux aux moteurs de recherche et perdre ainsi de 30 à 75% des visiteurs potentiels.
Premièrement, qu'une compagnie de service n'est pas nécessairement une compagnie capable de profiter du dialogue. Elle doit pour ça être ouvert à l'écoute. Ou plutôt que l'écoute soit un vecteur important pour sa croissance. Une boîte de RP (comme Edleman) l'est, par définition - elle doit être à l'écoute du marché.Effectivement, comme dans la majorité du secteur des affaires au Québec, très peu de joueurs sont à l'écoute du Web. C'est même exaspérant dans le secteur de la publicité, où seulement une infime part de leurs employés utilisent les carnets Web pour suivre les tendances du marché. Et c'est exactement la même chose pour les sites Web en général. Demande à n'importe quel patron le nombre de visiteurs que son site reçoit ? Il y a 8 chance sur 10 qu'il ne le sache pas où qu'il te donne des chiffres farfelus.
Deuxièmement, qu'une compagnie qui ne comprend pas ce qui m'enrichit n'est pas faite pour moi. Dont acte.
C'est exactement la même chose pour les producteurs de sites Web. Plus de 90% des boites qui concoivent des sites Web ne pensent pas a rendre les sites de leurs clients conviviaux aux moteurs de recherche et perdre ainsi de 30 à 75% des visiteurs potentiels.
15 sept. 2006
Microsoft disparaît du Web
C'est presque vrai dans un sens. Il n'apparait plus dans les rapports de statistiques de vos fichiers journaux (log files) et dans les services de statistiques en ligne que j'ai testé (WebStats, Site Meter, Webstats4you). Seul le service de Google Analytics m'affiche toujours les référents de MSN.
Tout ceci est dû à l'utilisation d'un javascript (gping="/GLinkPing.aspx?) utilisé dans les liens des résultats qui enlève les informations inhérentes au référents comme le site d'où vient le visiteur et les mots-clés utilisés dans sa recherche. Cette dernière information est d'ailleur primordiale pour les personnes en charge du marketing et les rédacteurs.
Mise à jour 21 sept : Maintenant corrigé
Technorati Tags: live+search, log+files, statistiques, analytics
Tout ceci est dû à l'utilisation d'un javascript (gping="/GLinkPing.aspx?) utilisé dans les liens des résultats qui enlève les informations inhérentes au référents comme le site d'où vient le visiteur et les mots-clés utilisés dans sa recherche. Cette dernière information est d'ailleur primordiale pour les personnes en charge du marketing et les rédacteurs.
Mise à jour 21 sept : Maintenant corrigé
Technorati Tags: live+search, log+files, statistiques, analytics
Hittail : Un service d'optimisation automatique
Assez surprenant comme nouveau service. Cela ce décline comme une solution d'analyse automatique de mots-clés négligés (ayant du potentiel) à partir de code de pistage sur votre site.
Ceci n'est rien de bien nouveau. La première chose que j'enseigne à mes clients est justement de regarder leur référents-moteur (visiteur provenant des moteurs de recherche avec l'expression-clé utilisée) et de transmettre cette liste de mots-clés aux rédacteurs pour qu'ils utilisent, -si possible-, des synonymes de ces mots-clés à l'avenir dans leurs textes.
Simple logique !
Pourquoi réutilisé les mêmes mots-clés qui vous apportent déjà des visiteurs alors que vous pourriez élargir votre éventail avec des expressions clés similaires ayant du potentiel en vérifiant avec des outils comme Overture.
Le bon coté de ce service est qu'il ouvrira les yeux de certains clients qui pensent qu'en optimisant 10 pages de chaque langue de leur site, l'affaire est faîte. Cela n'est pas la bonne méthode.
Il faudra toujours des humains pour dénicher les bons mots, - et surtout -, les bons endroits pour les utilisés.
Ceci n'est rien de bien nouveau. La première chose que j'enseigne à mes clients est justement de regarder leur référents-moteur (visiteur provenant des moteurs de recherche avec l'expression-clé utilisée) et de transmettre cette liste de mots-clés aux rédacteurs pour qu'ils utilisent, -si possible-, des synonymes de ces mots-clés à l'avenir dans leurs textes.
Simple logique !
Pourquoi réutilisé les mêmes mots-clés qui vous apportent déjà des visiteurs alors que vous pourriez élargir votre éventail avec des expressions clés similaires ayant du potentiel en vérifiant avec des outils comme Overture.
Le bon coté de ce service est qu'il ouvrira les yeux de certains clients qui pensent qu'en optimisant 10 pages de chaque langue de leur site, l'affaire est faîte. Cela n'est pas la bonne méthode.
Il faudra toujours des humains pour dénicher les bons mots, - et surtout -, les bons endroits pour les utilisés.
14 sept. 2006
Les revers du Web 2.0
Web 2.0 par si, Web 2.0 par là, c'est bien beau le 2.0 mais il ne faut pas oublier que cela dérape aussi. Exemples :
- Les foutus spams dans les commentaires ou dans les forums
- La gestion légale de l'informations des commentaires ou forums
- Les zillions de billets qui parlent tous du même article sans vraiment de valeur ajouté
- Des sites aspirateurs de billets que pour vendre des publicités
- La dérive des algorithmes de classification qui t'envoie sur un zolie petit vidéo quand tu es sur Digg pour des articles sur la technologie
- Les manipulations de paquetages de votes
- Les réseaux sociaux bâtit grâce au spam.
- L'envahissement des réseaux sociaux par les gens de marketing
- Des sites poubelle à publicité
Les lecons a tirer d'une catatrophe
Les évènements cahotiques d'hier devraient faire réfléchir plus d'un gestionnaires des communications. Les sites Web de plusieurs médias québécois et la surcharge des réseaux de téléphonie cellulaire ont rendus cahotique le suivit des informations. Cela n'est vraiment pas idéal en cas de crise où justement l'accès à l'information peut être capitale dans certains cas.
Gestion du pic d'affluence
Une page Web allégée devrait être prête a recevoir les informations les plus pertinentes en cas de crise. Une redirection de la page d'accueil habituelle vers cette page soulegera ainsi le(s) serveur(s). C'est d'ailleur ce qu'avait fait CNN un certain jour septembre 2001 et c'est ce qu'a fait hier le site français de Canoe.
Tous les sites Web d'institution ou de moyenne à grosse compagnie devrait aussi être doté d'une telle page avec un accès externe avec gestionnaire de contenu et script de redirection pour mettre à jour les informations pertinentes en cas de crise.
Gestion innefficace des informations du public
Un autre lacune assez évidente pour toutes personnes qui ont suivit les médias Web hier était le chaos total des informations contradictoires. Les sites Web des grand médias gèrent de façon absolument archaïque la collecte d'informations du public.
Radio-Canada, CyberPresse, et TQS nous offre que des adresses de courriel et des numéros de téléphones, alors que sur Canoe/LCN je n'ai rien trouvez du tout !!!
Aucun formulaire qui me permettrait aisément d'envoyer de l'information textuelle et électronique (photos ou vidéos) du style qu'utilisent les grands réseaux sociaux existants à la mode comme les MySpace, Blogger, Flickr, YouTube ou DailyMotion sur la Toile. Pathétique !
Technorati Tags: dawson, médias, trafic, collecte+informations
Gestion du pic d'affluence
Une page Web allégée devrait être prête a recevoir les informations les plus pertinentes en cas de crise. Une redirection de la page d'accueil habituelle vers cette page soulegera ainsi le(s) serveur(s). C'est d'ailleur ce qu'avait fait CNN un certain jour septembre 2001 et c'est ce qu'a fait hier le site français de Canoe.
Tous les sites Web d'institution ou de moyenne à grosse compagnie devrait aussi être doté d'une telle page avec un accès externe avec gestionnaire de contenu et script de redirection pour mettre à jour les informations pertinentes en cas de crise.
Gestion innefficace des informations du public
Un autre lacune assez évidente pour toutes personnes qui ont suivit les médias Web hier était le chaos total des informations contradictoires. Les sites Web des grand médias gèrent de façon absolument archaïque la collecte d'informations du public.
Radio-Canada, CyberPresse, et TQS nous offre que des adresses de courriel et des numéros de téléphones, alors que sur Canoe/LCN je n'ai rien trouvez du tout !!!
Aucun formulaire qui me permettrait aisément d'envoyer de l'information textuelle et électronique (photos ou vidéos) du style qu'utilisent les grands réseaux sociaux existants à la mode comme les MySpace, Blogger, Flickr, YouTube ou DailyMotion sur la Toile. Pathétique !
Technorati Tags: dawson, médias, trafic, collecte+informations
13 sept. 2006
Fusillade au college Dawson
Encore un autre fusillade du type de la tragédie de la polytechnique ou de Columbine. Les médias québécois réagissent assez rapidement et font de plus en plus d'appel à tous pour avoir plus d'informations. Il y aurait deux un suspect de mort et probablement une demi-douzaine vingtaine de blessés.
Ce qui me surprend, c'est qu'encore en 2006, les infrastructures des réseaux téléphoniques et même les sites Web de certains médias et celui du collège sont assez affectés par cet évènements. Je trouve assez inconcevable que les réseaux de cellulaires et que le site du seul média national en français soit fortement affecté !
MàJ 15h : Des photos commencent a faire leurs apparitions sur Flickr.
MàJ 17h59 : Finalement une vingtaine de blessés, une jeune victime et un suspect abattu par la police.
Technorati Tags: dawson, college+dawson, fusillade,
Ce qui me surprend, c'est qu'encore en 2006, les infrastructures des réseaux téléphoniques et même les sites Web de certains médias et celui du collège sont assez affectés par cet évènements. Je trouve assez inconcevable que les réseaux de cellulaires et que le site du seul média national en français soit fortement affecté !
MàJ 15h : Des photos commencent a faire leurs apparitions sur Flickr.
MàJ 17h59 : Finalement une vingtaine de blessés, une jeune victime et un suspect abattu par la police.
Technorati Tags: dawson, college+dawson, fusillade,
CNN et AOL pousse un peu fort
 * Visible aux États-Unis seulement.
* Visible aux États-Unis seulement.Après un bref coup d'oeil, je croyais que c'était simplement un liste de mots-clés contenant des noms de vedettes mal géré, mais le descriptif de la publicité nous montre que CNN a bien intentionnellement utilisé la mort du fils d'une vedette pour s'attirer des lecteurs. Et ce n'est pas malheureusement pas les seuls a utiliser cette forme morbide de publicité comme le montre cette autre capture d'écran où une autre publicité de Starware et d'AOL à droite (non-visible ici) utilisent cet évènement pour faire de la publicité !

7 sept. 2006
Zippy : Un métamoteur surprenant

Zippy.co.uk est un métamoteur qui utilisent plusieurs sources pour vous présenter ses résultats. Il utilise principalement les 4 grands (Google, Yahoo, MSN et Ask) pour ses résultats en plus d'offrir les données d'Alexa, de Technorati et celles de Internet Archive.
J'ai testé une foule de moteurs et méta-moteurs depuis ces 12 dernières années et je suis très impressionné par ses résultats. En plus des résultats classiques, il permet aussi d'avoir des informations stratégiques sur les sites comme les données d'Alexa, le PageRank, les liens externes, le nombre de pages indexés, etc.
Grâce au recoupement des résultats des 4 grands (GYMA) et en utilisant le nom de domaine, il permet aussi de voir les pages ou billets les plus populaires d'un site quand ces pages sont positionnés par plus d'un moteur.
À découvrir !
PS: Je parie que vous trouverez des informations sur vous que vous n'aviez jamais vu ailleur !
Technorati Tags: metamoteur, zippy
6 sept. 2006
Google News Archive : Un premier pas vers des archives libres !
Enfin des recherches dans de multiple archives Web. Surtout après 3 ans où il nous avait été possible de tâter pendant une courte semaine la recherche sur Web Archive d'Alexa. Évidemment, ce n'est qu'une infime partie des archives qui sont accessible et encore une plus petite partie qui sont libre de droit, mais c'est le pied dans la porte.
Les archives sont pour le moment principalement anglaises mais heureusement deux joueurs québécois, Canoe/LCN et le journal Le Devoir vont parfois percés les résultats. Du coté de nos cousins ; Le Monde, Libération, Le Nouvel observateur et L'Expansion sont aussi présent.
Utilisation
Les archives peuvent être affiché selon deux critères, par le critère Timeline qui est très minimaliste et par articles où la fouille se fait plus en profondeur.
Est-ce la naptérisation d'un autre modèle archaïque ?
Il y a fort a parier qu'un des détenteurs d'archives historiques fera le saut bientôt et qu'évidemment les autres suivront. Le modèle économique archaïque de faire payer l'utilisateur jusqu'à 5$ pour pouvoir consulter un simple article n'a jamais été très viable et le sera de moins en moins. On n'est plus du temps des micro-films et les éditeurs devraient se sortir la tête du sable.
L'ouverture des archives contenant des milliers d'articles au public résoudra deux des grands problèmes actuel des médias et ne nécessite qu'une très simple opération.
L'accès à un plus grand nombre de pages aisément ciblables pour les annonceurs, une plus grande notoriété pour le site - et une autorité (pagerank) accru - et des retombés économiques non négligeables pour le média.
Les archives sont pour le moment principalement anglaises mais heureusement deux joueurs québécois, Canoe/LCN et le journal Le Devoir vont parfois percés les résultats. Du coté de nos cousins ; Le Monde, Libération, Le Nouvel observateur et L'Expansion sont aussi présent.
Utilisation
Les archives peuvent être affiché selon deux critères, par le critère Timeline qui est très minimaliste et par articles où la fouille se fait plus en profondeur.
Est-ce la naptérisation d'un autre modèle archaïque ?
Il y a fort a parier qu'un des détenteurs d'archives historiques fera le saut bientôt et qu'évidemment les autres suivront. Le modèle économique archaïque de faire payer l'utilisateur jusqu'à 5$ pour pouvoir consulter un simple article n'a jamais été très viable et le sera de moins en moins. On n'est plus du temps des micro-films et les éditeurs devraient se sortir la tête du sable.
L'ouverture des archives contenant des milliers d'articles au public résoudra deux des grands problèmes actuel des médias et ne nécessite qu'une très simple opération.
L'accès à un plus grand nombre de pages aisément ciblables pour les annonceurs, une plus grande notoriété pour le site - et une autorité (pagerank) accru - et des retombés économiques non négligeables pour le média.
3 sept. 2006
Calcul humain de masse et Etiquetage ludique 2.0
Au départ, j'étais un peu sceptique sur le concept du jeu du Google Images Labeler et surtout de la valeur des résultats.
L'idée ici est de résoudre un des grands problèmes informatique, la reconnaissance et l'étiquetage sémantique de photographies et d'images. Les ordinateurs sont impuissant à l'heure actuelle a résoudre ce problème. Comme il y a des centaines de millions d'images et de photographies sur le Web sans valeur informationnelle précise, le problème est titanesque. Et l'informatique actuellle est impuissante à résoudre ce problème. La preuve ultime de ce constat est l'utilisation de CAPTCHA sur les formulaire, pour s'assurer que c'est bien un humain qui remplit le formulaire en question et non pas un programme informatique créer pour flouer le formulaire ou sondage en ligne. Assez paradoxal tout de même de créer un programme informatique que seul l'humain pourra résoudre !
Solution : L'ESP Game qui inspira le Google Image Labeler
Le jeu consiste a mettre en temps réel deux joueurs au hasard ensemble (ceci pour empêcher le SPAM) pour qu'ils puissent étiqueter (tag) des photos provenant de Google Image. Comme le jeu est chronométré, la pertinance des mots-clés doit en patir me dis-je.
Comment bien définir une photo de Martha Stewart par exemple ? Le premier mot venant à l'esprit est "femme" évidemment, mais ceci n'est pas très sémantiquement précis. "Femme d'affaires" ou "Martha Stewart" serait déja mieux. "Criminelle" pourrait aussi lui convenir. Alors comment gérer ces multiples possibilités ?
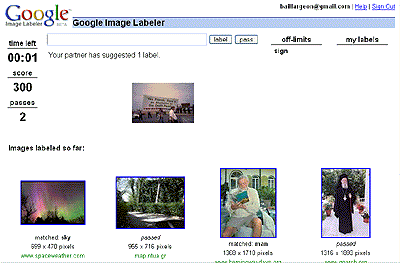
Tout simplement en re-soumettant une même image plusieurs fois à différents joueurs en leurs mentionnant que certaines étiquettes sont déja utilisées comme le "Off Limits" dans le jeu présenté ci-haut. Ce concept assez génial d'utiliser le procrastinateur internet comme main d'oeuvre gratuite vient du chercheur américain Luis von Ahn du département de science informatique de l'université Carnegie Mellon. Voir cette excellente présentation du bonhommme en question.
Possible d'étiqueter la grande majorité des images du Web ?
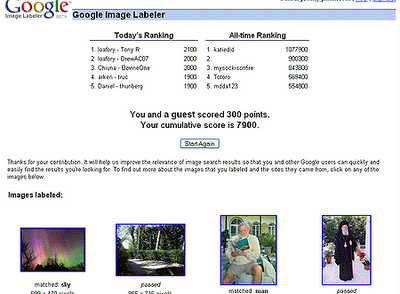 Certains en doute, mais moins de 100 heures après le lancement du jeu, les 5 joueurs les plus "intoxiqués" par ce jeux ont déja étiquetés, - à eux cinq seulement-, près de 50,000 images !
Certains en doute, mais moins de 100 heures après le lancement du jeu, les 5 joueurs les plus "intoxiqués" par ce jeux ont déja étiquetés, - à eux cinq seulement-, près de 50,000 images !
Génial !!!
Technorati Tags: google+images+labeler,, tagging, étiquetage, sémantique, jeux, calcul+humain+de+masse
L'idée ici est de résoudre un des grands problèmes informatique, la reconnaissance et l'étiquetage sémantique de photographies et d'images. Les ordinateurs sont impuissant à l'heure actuelle a résoudre ce problème. Comme il y a des centaines de millions d'images et de photographies sur le Web sans valeur informationnelle précise, le problème est titanesque. Et l'informatique actuellle est impuissante à résoudre ce problème. La preuve ultime de ce constat est l'utilisation de CAPTCHA sur les formulaire, pour s'assurer que c'est bien un humain qui remplit le formulaire en question et non pas un programme informatique créer pour flouer le formulaire ou sondage en ligne. Assez paradoxal tout de même de créer un programme informatique que seul l'humain pourra résoudre !
Solution : L'ESP Game qui inspira le Google Image Labeler
Le jeu consiste a mettre en temps réel deux joueurs au hasard ensemble (ceci pour empêcher le SPAM) pour qu'ils puissent étiqueter (tag) des photos provenant de Google Image. Comme le jeu est chronométré, la pertinance des mots-clés doit en patir me dis-je.
Comment bien définir une photo de Martha Stewart par exemple ? Le premier mot venant à l'esprit est "femme" évidemment, mais ceci n'est pas très sémantiquement précis. "Femme d'affaires" ou "Martha Stewart" serait déja mieux. "Criminelle" pourrait aussi lui convenir. Alors comment gérer ces multiples possibilités ?

Tout simplement en re-soumettant une même image plusieurs fois à différents joueurs en leurs mentionnant que certaines étiquettes sont déja utilisées comme le "Off Limits" dans le jeu présenté ci-haut. Ce concept assez génial d'utiliser le procrastinateur internet comme main d'oeuvre gratuite vient du chercheur américain Luis von Ahn du département de science informatique de l'université Carnegie Mellon. Voir cette excellente présentation du bonhommme en question.
Possible d'étiqueter la grande majorité des images du Web ?
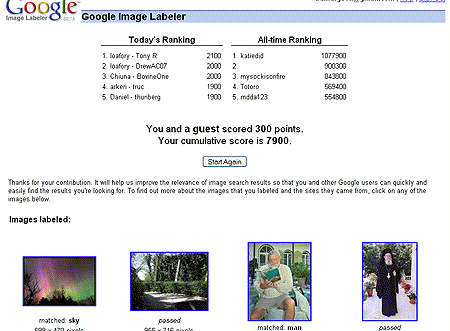 Certains en doute, mais moins de 100 heures après le lancement du jeu, les 5 joueurs les plus "intoxiqués" par ce jeux ont déja étiquetés, - à eux cinq seulement-, près de 50,000 images !
Certains en doute, mais moins de 100 heures après le lancement du jeu, les 5 joueurs les plus "intoxiqués" par ce jeux ont déja étiquetés, - à eux cinq seulement-, près de 50,000 images !Génial !!!
Technorati Tags: google+images+labeler,, tagging, étiquetage, sémantique, jeux, calcul+humain+de+masse
S'abonner à :
Messages (Atom)